Highlight

Gemeinsam erfolgreich – unser valantic Team.
Lernen Sie die Menschen kennen, die mit Leidenschaft und Verantwortung bei valantic Großes bewegen.
Mehr über uns erfahrenDer letzte Blogpost fasste die verschiedenen Updates der SAP Datasphere im Jahr 2024 zusammen und gab einen Ausblick auf die spannenden Themen, die dieses Jahr erwartet werden. Seitdem wurden bereits einige Innovationen umgesetzt. Denn neben dem neuen Design „Horizon“, dass sich durch moderne und lebendige Farben hervorhebt, wurde die SAP Datasphere um einige Funktionen erweitert. Das neue Design veränderte einige Symbole, aber alle Funktionalitäten bleiben unverändert.
Im Folgenden sollen eine Zusammenfassung der spannendsten Innovationen, die seit Januar veröffentlich wurden, erfolgen. Die Datenmodellierung und Datenintegration stehen diesmal im Mittelpunkt, aber auch Themen wie die Administration, der Data Catalog und Marketplace werden von der SAP aufgegriffen.
Für den Erfolg eines Unternehmens ist die Verarbeitung großer Datenmengen entscheidend. Um den Arbeitsfluss möglichst nicht zu beeinträchtigen, sollte dies möglichst effizient umgesetzt werden können.
Dazu wurde die RFC (Remote Function Call) – Performance für Replikationsflüsse von SAP-S/4HANA-On-Premise-Verbindungen optimiert. Für bereits bestehende Verbindungen lässt sich jetzt die RFC-Schnellserialisierung aktivieren. Dies verbessert insbesondere bei großen Datenmengen die Performance. Falls eine neue Verbindung angelegt wird, ist die Schnellserialisierung nun standardmäßig eingeschaltet.
Bei aktiven Replikationsflüssen gibt es bereits die Möglichkeit Objekte zu entfernen, während bereits existierende Daten im Ziel erhalten bleiben. Ebenso lassen sich neue Objekte aus dem Quellsystem hinzufügen. Als dritte Neuerung lassen sich die Intervalle für die Delta-Datenübernahme bei einem aktiven Replikationsfluss verändern. Dadurch werden Unterbrechungen noch seltener notwendig und häufige Änderungen können problemlos durchgeführt werden.
Außerdem verringert sich bei den Replikationsflüssen der Anteil an den manuellen Arbeiten. Falls eine Spalte aus der Zieltabelle nicht im Quellsystem enthalten ist, kann diese jetzt ignoriert und die restliche Replikation erfolgreich abgeschlossen werden. Vorher war es notwendig in der Zieltabelle, alle nicht vorhandenen Spalten per Hand zu löschen.
Neben den Replikationsflüssen erhalten zudem die Transformationsflüsse zwei nützliche Erweiterungen zur Analyse und Anpassung. Zukünftig lässt sich ein Lauf des Transformationsflusses simulieren, um zu überprüfen ob auch das gewünschte Ergebnis erzielt wird, ohne dabei die Änderungen in der Ziel-Tabelle zu speichern. So können ebenso gleichzeitig etwaige Fehler oder Performance-Probleme erkannt und behoben werden.
Wenn eine Simulation für die Analyse und Fehlerbehebung nicht ausreicht, lässt sich zukünftig eine PLV-Datei (SQL-Planvisualisierungs-Datei) generieren und herunterladen. Hierdurch erhalten User die Möglichkeit einen visuellen Einblick in die Operatoren und deren Beziehungen sowie den Hierarchien untereinander zu bekommen. Diese detaillierten Informationen zu dem Datenmodell ermöglichen eine praktische Option zur Planung von Änderungen und des Abschätzens der Auswirkungen. Für das Anzeigen der PLV-Datei wird ein kompatibles SQL-Planvisualisierungs-Tool benötigt, wie zum Beispiel das SQL-Analyzer-Tool für SAP HANA.
Auf Seiten der Analysefunktionalität wurde der View-Analyzer angepasst und erweitert. Die Laufdetails, Aufgabenprotokolle und die View-Partitionierung wurden hinsichtlich der Benutzerfreundlichkeit verfeinert, was die Verwendung und den Einstieg erleichtert. Hinzugekommen ist ebenfalls die Funktion, dass auch lokale Tabellen bei der Datenpersistenz-Kandidatenbewertung analysiert werden. Diese wurden vorher in keiner Metrik zur Bewertung betrachtet, wodurch die Kennzahlen allerdings weniger aussagekräftig waren. So können User*innen bisherige Entscheidungen zur Persistenz erneut analysieren und Entscheidungen anpassen.
Bei den Neuerungen der Datenmodellierung richten sich der Fokus zunächst auf das Analysemodell. Hier werden häufig viele Dimensionen genutzt, sowie Attribute dupliziert. Diesen können jetzt ebenfalls technische Namen zugewiesen werden, wodurch eine einheitlichere Benennung ermöglicht und die Übersicht verbessert wird. Im Zuge dessen wurde für die konsistente Benennung gleichzeitig der Dimensions-Alias in Betriebswirtschaftlicher Name umbenannt, wie es bereits aus Views und Tabellen bekannt ist.
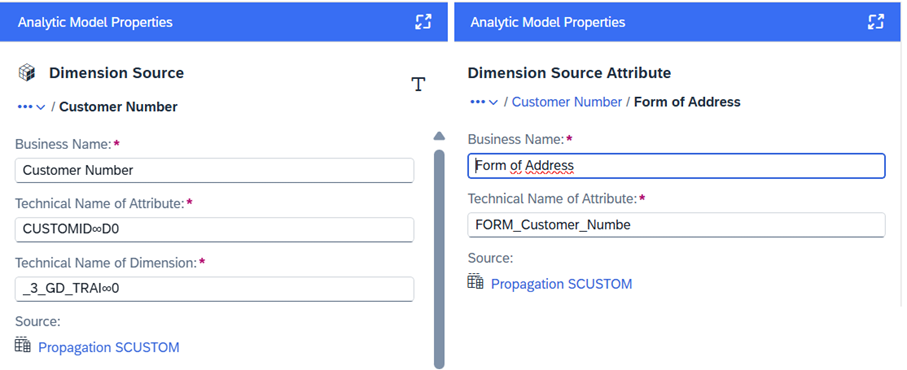
Der Status eines aktivierten Analysemodells wird auf „Zu aktivierende Änderungen“ oder „Entwurfsfehlers“ geändert, falls sich die Hierarchie in einer verwendeten Dimension ändert. Der Status ist abhängig von den Auswirkungen der Änderungen.
Das Anzeigen des veränderten Status wird insbesondere interessant mit Perspektive auf eine Neuerung in den Hierarchien. Vorher war die Identifizierung einer Hierarchie im Hierarchieverzeichnis nur durch eine einzige Schlüsselspalte unter der Eigenschaft „Spalte vom Typ Hierarchiename“ möglich. Diese Eigenschaft wurde in „Hierarchieverzeichnisassoziation“ umbenannt. Dort muss eine Assoziation, die auf das Hierarchieverzeichnis verweist, eingetragen sein. Zudem werden dadurch die Assoziationen mit zusammengesetzten Schlüsseln möglich. Bereits vorhandene Hierarchien werden automatisch migriert, somit wird der Status des Analysemodells bei Nutzung dieser neu gesetzt.
Eine weitere Neuerung am Analysemodell, die aufgeführt werden kann ist, dass sich dynamische Standardwerte für Variablen setzen lassen. Diese können dann in der Analysevorschau und ebenfalls in der Variableneingabeaufforderung der SAP Analytics Cloud dynamisch vorgeschlagen werden.
Durch eine zusätzliche Erweiterung können die Datenzugriffskontrollen für dynamische filterbasierte Operatoren und Werte, sowie statische Hierarchien und Einzelwerte, kombiniert werden. Somit lässt sich auch bei vielseitigen oder großen Analysemodellen der Datenschutz gewährleisten.Ein weiteres interessantes Update bezieht sich unter anderem auch auf die Analysemodelle.
Es ist ab jetzt möglich eine Liste von früheren Objektversionen abzurufen und folgende Aktionen auszuführen:
Mit dem letzten Punkt können so veraltete Versionen von lokalen Tabellen gelöscht werden, falls die Daten bereits in Flüssen verarbeitet worden sind. Hierbei kann die Performance und Speichereffizienz des Systems verbessert werden.
Falls die lokalen Tabellen eine aktivierte Delta-Erfassung haben, kommt noch eine weitere und konsistente Neuerung für diese hinzu, um ebenfalls die Performance und Speichereffizienz des Systems zu optimieren. Hier lassen sich Datensätze wie folgt löschen, falls die Datenänderung bereits verarbeitet worden sind:
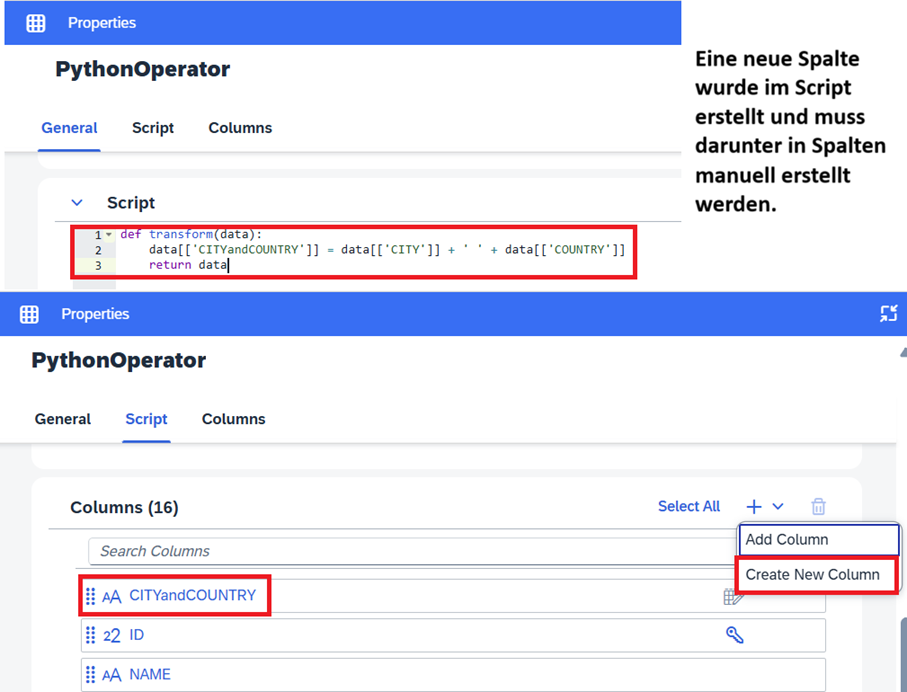
In Datenflüssen wurde die Möglichkeit für den Einsatz von Python erweitert. Die eingehenden Daten beim Python-Operator können umgewandelt werden. Im Anschluss können die strukturierten Daten an den nächsten Operator übergeben werden. Im Python-Operator können beispielsweise Name und Datentyp einer Spalte geändert werden. Es ist ebenso möglich Spalten zu löschen und hinzuzufügen. Dabei gilt es zu beachten, falls eine Spalte im Bereich „Script“ des Python-Operator hinzugefügt wird, wird diese nicht automatisch propagiert und ist somit im nächsten Operator nicht verfügbar. Es ist notwendig die neue Spalte auch im Bereich „Spalten“ des Python-Operators per Hand einzufügen, da es sonst zu Fehlern kommen kann. Die Einschränkungen im Python Bereich finden Sie weiterhin unter der SAP-Python-Operator Referenz.
Ebenfalls gibt es im Bereich der SQL-View-Transformationen eine kurze, aber nicht weniger wichtige Innovation. Bei aktiven SQL-View-Transformationen gibt es die Option der Datenvorschau. Dadurch lassen sich Änderungen schneller analysieren und es ist z.B. nicht mehr notwendig eine weitere View zu erstellen, um eine Vorschau der Daten zu erhalten.
Für die Administration ist die Einführung der DW AI Consumer Rolle eine bedeutende Innovation. Wahlweise kann einer benutzerdefinierten Rolle das Recht auf Data Warehouse KI-Nutzung zugeteilt werden. Die Suche in natürlicher Sprache im Bereich des Data Builders und im Repository-Explorer werden dadurch unterstützt und die Eingabe wird mittels KI interpretiert. Dadurch fällt die Notwendigkeit der zeichengenauen Eingabe weg. Zu weiteren Möglichkeiten im Datenkatalog mehr im Abschnitt Datenkatalog & Datenmarktplatz. Es wird allerdings eine Lizenz für SAP-AI-Einheiten benötigt. Diese kann von einem Kundenbetreuer erhalten werden.
Um Ressourcen auch kurzfristig neu zu verteilen, wurde die Option geschaffen, Task Chains abzubrechen. Dies kann notwendig sein, falls diese unerwartet viel Zeit oder Ressourcen benötigen und negative Auswirkungen auf andere Task Chains hat. Zeitgleich ergibt sich die Möglichkeit auf spontane Ressourcenanforderungen zu reagieren und bestimmte Task Chains manuell steuern zu wollen, obwohl diese bereits gestartet worden sind.
Data Catalog und Data Marketplace werden dieses Mal unter einem Blogpost-Eintrag zusammengefasst, da die SAP Datasphere ebenfalls diesen Weg einschlägt. Als wichtige Innovation werden diese jetzt in einem Menüpunkt in der Seitennavigation kombiniert. Ein zentraler Punkt um Assets und Daten, sowie ihrer Metadaten zu verwalten und zeitlich auch Lizenzen zu verwalten und sich an für Sie interessanten Themengebieten zu beteiligen. Dadurch werden unter demselben Zugriffspunkt folgende Funktionen erreicht:
Wie bereits erwähnt lässt sich die SAP Business KI für die Verwaltung und Anreicherung von Assets im Katalog nutzen. Hierbei lassen sich mit der SAP Business KI Zusammenfassungen und Langbeschreibungen generieren. Dazu gibt es im Bereich der „Katalog Details bearbeiten“ jetzt einen zusätzlichen Button „Zusammenfassung generieren“. Die gleiche Funktion findet sich auch unter „Inhalt bearbeiten“ für die Beschreibung durch den Button „Generieren“. Zusätzlich gibt es diese Option auf Unterstützung für die Tags im Bereich der „Semantischen Anreicherung“. Dort findet man diese in der Hierarchie, die die Tags enthält. Diese Unterstützung bietet eine zeitsparende Lösung und schnellere Übersicht für die Verwaltung und Anreicherung der Assets.
Im Datenkatalog gibt es nun auch die Auswirkungs- und Herkunftsanalyse, die einigen User bereits aus der Datenmodellierung bekannt sein dürfte. Dies stellt einen einfachen und entscheidenden Zugriff auf das Diagramm dar, um das Verständnis für ein Datenprodukt zu ermöglichen, um beispielsweise Vorteile des Produkts oder auch Einschränkungen zu erkennen.
Im ersten Quartal haben grade in der Datenmodellierung und Datenintegration viele neue Funktionen und Optimierungen Einzug in die SAP Datasphere gefunden. Die Performance wurde an einigen Stellen verbessert und gleichzeitig wurde das Analysemodell und die Basis dafür erweitert.
In den vergangenen Wochen führten wir unsere SAP Analytics Roadshow durch. In zahlreichen Städten, wie Hamburg, München, Köln und Kopenhagen kam ein SAP Analytics begeistertes Publikum zusammen. In spannenden Fachvorträgen berichteten valantic-Kunden über ihren Weg in die Cloud-Welt. Bei gemeinsamen Kaffee- und Mittagspausen wurden diese Ansätze diskutiert und sich ausgetauscht. Zudem war an jedem Standort die SAP anwesend und berichtete über die Intention und Strategie der Business Data Cloud. Das Fachpublikum konnte somit ihre Fragen direkt an die SAP richten. Die valantic Teamleads gaben in Vorträgen über die SAP Analytics Cloud und SAP Datasphere tiefe Einblicke in ihre Erfahrungen aus einer Vielzahl von Kundenprojekten. Ebenso wurde die aktuell viel thematisierte AI betrachtet. Ein Fachvortrag über die neuesten Technologien und deren Einsatz im Videoanalysesystem begeisterte das Publikum. Dieses Thema wurde mit einer Demonstration von valantic abgerundet, in dem die Videometadaten per Live-Connection in die SAP Datasphere integriert und modelliert sowie im Anschluss in der SAP Analytics Cloud gereportet wurden.
Falls Ihre Interessen geweckt wurden oder Sie allgemeine Fragen zur SAP Datasphere haben, stehen wir Ihnen gerne für Rückfragen zur Verfügung.

Live Demo
Wir freuen uns darauf, Ihnen die SAP Datasphere im Detail vorzustellen. Sprechen Sie uns gerne an!
Nichts verpassen.
Blogartikel abonnieren.

")